雖然「亂倉打鳥」輸入法對符號的支援已經達到令我滿意的程度,
但它的懶人詞庫說穿了對我一點用處也沒有!
藉由編輯它的對照表的過程,
我發現它其實並沒有支援 CJK 擴展 B 區的字元,
(擴展 A 區的可能也沒有支援;以下為方便解說,姑且把這些字稱作「罕見字」)
而且老實說,它的符號很多都變成了重碼字,有時反而降低輸入的速度,
於是我有了打造一套適合自己的「改良式倉頡輸入法」的計畫。
我的計畫是用「通用輸入法編輯工具」產生一個「泰瑞倉頡輸入法軟體」,
它必須支援用組字字根就能輸入多種符號,
又能符合多數人用第三代倉頡拆碼的習慣,
最重要的是要能包含所有的罕見字。
第一個要解決的問題是:
要先找到一個包含罕見字的「組字字根:詞組」對照表。
畢竟 CJK Ext-A、CJK Ext-B 合計近五萬個罕見字的組字字根,
如果要靠自己一個字、一個字建置的話,
實在是非常耗大的工程,所以用現成的對照表是最快的。
我本來打算找個可逆轉的軟體把「新倉頡輸入法 2007」
或「Vista 倉頡輸入法」這兩套軟體,
轉成符合「組字字根:詞組」對照表格式的文字檔,然後再來編修,
但一直找不到這樣的軟體
(只有找到簡體版的 imegen.exe,它只能逆轉 *.mb 格式的檔案;
另一個是 uni2txt.exe,它只能在命令模式下將嘸蝦米特定的 *.tab 檔,
也就是所謂的「參考檔」,轉成純文字檔。
但是,說穿了!這兩支程式對我這項計畫是沒有幫助的),
於是只好乖乖找「組字字根:詞組」對照表的文字檔。
後來,我找到了這個網頁:http://hyperrate.com/thread.php?tid=6172
下載它提供的 CIN 檔後,再以 Notepad++ 開啟,
結果發現它的格式和我之前所下載的「亂倉打鳥」的對照表格式相去不遠,
看來應該可以成功打造我想要的「泰瑞倉頡輸入法」。
本來我是嫌它的檔案日期有點舊,
因為它是拿「倉頡之友 。馬來西亞」在 2008 年 4 月 9 日
發表的「第五代倉頡輸入法」軟體來逆轉的。
按照它上面的指示連結到「倉頡之友 。馬來西亞」網站的話,
其實可以下載到 2008 年 10 月 24 日發表的「第五代倉頡輸入法」軟體,
我仿照它的程序進行逆轉後,
發現得到的文字檔格式是顛倒的「詞組:組字字根」對照表,
而且它的「詞組」與「組字字根」中間並沒有空白字元或分隔字元,
有的話,還好辦一點,因為可以用 Excel 轉換成表格,
再把兩欄對調,就能做成符合「通用輸入法編輯工具」所需的格式,
沒有的話,雖然也能用 Excel 硬割出一條分隔線,但總是比較麻煩。
再看到「倉頡之友 。馬來西亞」網站上所寫的更新記錄,
其實兩個不同日期的檔案所用的「組字字根:詞組」應該是一樣的,
於是只好安慰自己接受那個 CIN 檔。
「gcin」的網站除了提供這個 CIN 檔外,
還提供 17,654 字的補完 CIN 檔。
我早期做的「泰瑞倉頡輸入法」把這 17,654 個字包含進去,
以為做出這種支援 82,198 個漢字的改良式倉頡輸入法會是最好的,
因為它可以支援的漢字比 CJK 及其擴充 A、B 區的 70,195 個漢字還多。
結果是:即使在 Vista 或已安裝「新細明體更新套件」的 XP 環境下
(意即「可顯示 CJK 及 CJK Ext-A、CJK Ext-B 字元」的環境下),
一些候選字會顯示成「□」(可直接出字的詞組也有這樣的問題),
原因是它們要在「支援別的 Unicode Block 字元的字型」下才能正常顯示,
但這種字型並不好找,
以致於讓產生的輸入法軟體會有「可拆出字但卻顯示不出字」的現象,
有鑑於此,後來我又重做一個對照表,這次就不納入這些「補完」的字,
所以「泰瑞倉頡輸入法對照表」不包含這 17,654 個漢字。
第二個要解決的問題是:
要確認 CJK、CJK Ext-A、CJK Ext-B 的每個漢字都被包含在對照表裡。
我先上「倉頡之友 。馬來西亞」網站的「漢字碼表」網頁,
記下各區第一個字及最後一個字,
再到這個「字元各種碼位表示法轉換」網頁,
算出各區第一個字及最後一個字的「Decimal NCRs」(十進位碼),
把第一個字的「Decimal NCRs」貼到 Excel 裡,
再用數字拖曳後會產生序列數字(即「向下填滿」)的功能
(拖曳到產生各區最後一個字的十進位碼為止),
來得到這三個 Unicode Block 的「Decimal NCRs」,
再用「字元各種碼位表示法轉換」逆轉回為漢字,
最後再貼回 Excel 中,
並把「Decimal NCRs」修改為「Decimal code points」,
這樣就得到「Decimal code points」與其對應漢字的檔案,
我把它們分為「CJK」、「CJK-Ext-A」、「CJK-Ext-B」三個工作表,
以方便後續的處理。
然後,我又把上述 CIN 檔的內容貼到 Excel 的工作表中,
貼上後讓組字字根在 A 欄,詞組(單一漢字)在 B 欄,
把漢字那欄分次(一次一萬字)用上述那個「字元各種碼位表示法轉換」網頁,
算出其對應的「Decimal code points」;
算出後還要用 Word 將 9,999 個分隔的「 10 」取代為「^p」(斷行符號),
然後貼到 Excel 工作表的 C 欄,
再對「Decimal code points」進行排序,
接著用「進階篩選」的功能,把重複的漢字去除
(重複的原因是因為有些字會有不同的拆法),
將去除的結果放在 D 欄,
再把這個工作表取名為「THCJ5」。
去除重複之後,接著要檢查有沒有跳號(遺漏)的問題,
我把「THCJ5」工作表裡,排序且篩選後的「Decimal code points」這欄貼到
「CJK」、「CJK-Ext-A」、「CJK-Ext-B」三個工作表的 C 欄,
如果用「向下填滿」功能產生的不重複、不跳號的 A 欄數值,
除以可能有跳號的 C 欄數值後,
得到的結果不是「1」的話,代表從不是「1」的那列開始發生跳號,
就記下跳號的「Decimal code points」,
並在 C 欄補上這個跳號的「Decimal code points」,
然後重新運行這個除法規則,
如此反覆進行,就能用這種方式找到所有跳號的地方
(因為我不會寫程式,也不知道有沒有好的 Excel 函數或功能可以用,
所以只好用這種最笨的方法)
我找到的結果是:
這 6 個十進位碼(字)發生了跳號:
28490(潊)
40472(鸘)
138128()
145970()
146668()
163968()
於是我在「THCJ5」工作表的 A、B、C 欄裡,
為這六個字補上應有的組字字根、字元、十進位碼。
不過我用 EditPlus 尋找原始 CIN 檔內容的話,
並沒有缺少這 6 個字的情形,
可能是先前製作最早期的「泰瑞倉頡輸入法對照表」時,
曾使用 Notepad++ 將 CIN 檔的編碼從「UTF-8」轉為「Unicode Little-Endian」
(這是「通用輸入法編輯工具」要求的編碼格式),
和用 Notepad++ 複製、貼上這些罕見字時,似乎有支援程度不佳的問題
(就連 EditPlus 在顯示 CJK Ext-B 的漢字時也不是很正常。
不過我還是建議各位用 EditPlus 3 或 Notepad2 做編輯的工作,
畢竟它在設定字型為「新細明體」後,
在 EditPlus 或 Notepad2 裡可顯示的字元與候選字窗格可顯示的字元會較一致,
至於 Notepad++ 就不要用了)。
第三個要解決的問題是:
要兼容第三代與第五代的取碼方式。
由於這個 CIN 檔的組字字根用的是第五代倉頡,
和我們一般早已經習慣的第三代倉頡是有落差的,
像「作」字,第三代倉頡碼是「人竹尸」,但第五代的是「人人尸」,
為了不影響原來的輸入習慣,
有必要找出第五代倉頡廢除了哪些字的第三代倉頡碼,
然後為這些字添加符合第三代倉頡的「組字字根:詞組」。
再經過一番搜尋後,
我在「鯨魚、我的倉頡輸入法」網站上找到了這個檔案:
http://www.reocities.com/Baja/Mesa/2118/ftp/cj3vs5.txt
雖然它只列出被刪除的第三代倉頡碼的「Big5 碼」字元,
但有勝於無,只好勉強接受!
我用 Excel 的篩選功能,把它的第三代倉頡碼複製出來,
添加到上述的「THCJ5」工作表裡,
最後把這個「THCJ5」工作表的 A、B 欄做成 Unicode 格式的文字檔,
並調整了格式,以符合「通用輸入法編輯工具」的要求,
我把它取名為「THCJ5.txt」。
最後就是加入「亂倉打鳥」的符號了!
有鑑於「亂倉打鳥」的對照表裡,
兩個字(含)以上的詞組其實對於熟練倉頡的人是用不到的,
所以我做的對照表把它們全部刪除了!
這樣可以符合傳統倉頡使用者的需求,
又可加快「通用輸入法編輯工具」産生輸入法軟體的速度。
另外,因為有些符號並不能正常顯示在候選字視窗裡,
我把這類的符號一一刪除,並做了一些調整。
最後把彙整好的「THCJ5.txt」裡的「組字字根 詞組」貼到新的 Excel 工作表裡,
這次只放在 A 欄,也就是 A 欄是「組字字根 詞組」的格式,
再用「進階篩選」的功能去除重複的部份
(「亂倉打鳥」的「組字字根 詞組」其實有很多列是重複的,
我彙整的 THCJ5.txt 裡也有一些重複的),
再貼回「THCJ5.txt」,取代原本的內容,
不過這次又遇到阿飄了!
沒有重複的「焘」字居然無故被剔除,
而且很多希臘字母大小寫被視為相同的字元而被剔除,
(本來該有的「㋀」至「㋋」、「㏠」至「㏾」、「㍙」至「㍰」,也只剩下「㋀」),
於是只好用人工方式補回去,
最後加上「/S」的可用按鍵宣告,就完成了這個完美的對照表。
我把用它來産生的輸入法叫「泰倉」(泰瑞倉頡)輸入法,
簡稱「泰倉」(很自戀的一種做法  )!
)!
延續「亂倉打鳥輸入法」的精神,符號的輸入方式如下:
【,】、 【.】、 【'】、 【[]】、 【,,】、 【./】、 【;】、 【;;】、【...】,分別是
【,】、【。】、【、】、【「」】、【!】、【?】、【;】、【:】、【…】的快速鍵。
正式版本的泰瑞倉頡輸入法的「組字字根:詞組」對照表的下載網址是:
http://www.mediafire.com/file/cwicp98a065lxda/THCJ5.zip
使用「通用輸入法編輯工具」産生新的輸入法軟體之前,
記得可以編輯其中的「blog」、「http://」成為你專屬的網址,
想要更多變化的人,可以儘管大膽的修改!
下圖展示我努力的成果:
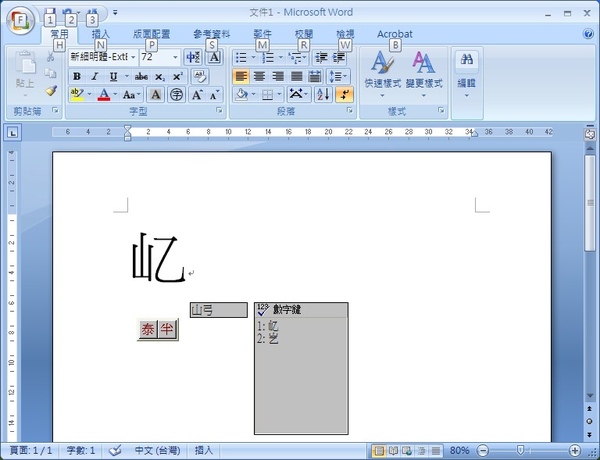
基本上,要顯示這些擴充 A、B 區的字元要具備下列條件:
作業系統為 Windows Vista、Windows Server 2008 或以後版本的 Windows;
或是已安裝「新細明體更新套件」的 Windows XP、Windows Server 2003。
字型方面也要做些設定才行,
在 WinXP + Word 中可以將這些罕見字的字型設定為「新細明體-ExtB」,
就能正常顯示了!


 留言列表
留言列表